My recent LLM experiment
People are talking about Large language model and release many product that applied LLM everyday. The developers at my company are also using LLM especially OpenAI to help speed up development work, Large Language Models (LLMs) are transforming the way our software is developed. Using OpenAI is fast and easy, but it comes with cost and privacy concerns, we have to pay monthly cost to use OpenAI API and we do not know our prompt/query may or may not be used for other purpose. On the other side, free models usually do not have good quality and are usually slow, difficult to run locally, even with powerful GPU server.
Also LLMs which support Vietnamese are not main-stream, they are there but mostly finetuned model, I’ve try some but actually there’s no that fit my requirements.
In this blog post, I will cover my experiment getting 7B model running locally, we then cover how to build application using vLLM, apply RAG, prepare dataset to finetune an LLM model using 2 different approaches.
On the other hand, in real world application I managed to get Vision language and audio model to run along with LLMs to accomplish more complicated task, however those will not be covered this time.
- Past Experiment
- Huggingface transformers
- vllm
- LLM application
- Performance testing
- RAG
- Finetune a model
- Conclusion
Past Experiment
My first experiment with LLM is the project we built during Hackathon last year, apply Retrieval-augmented generation (RAG) with langchain and OpenAI gpt-3 model to build chatbot to help user quickly buy items on our fintech application using natural (Vietnamese) language, we didn’t win but that 2 days was fun. I didn’t intent to use OpenAI, at first I tried to use different LLM models such as Open Assistant, Llama, etc but again, those were slow and low quality, using OpenAI for 24 hours competition was reasonable at that time.
A few days ago I decide to try local approach again because after 1 year long people are still working so hard to build many different model with promise to have better precision, faster, easier to use and better quality. After some quick research, the model I choose is Qwen2 - developed by Qwen team, Alibaba Cloud. I choose this model because:
- It’s opensource and free for commercial use (Apache License)
- It support Vietnamese out-of-the-box
- When getting asked with sensitive question to Vietnamese people, its response is acceptable
Luckily one of my friend is nice enough when I asked to borrow a GPU server to run this experiment, server hardware is as following:
CPU: Intel(R) Xeon(R) CPU E5-2683 v4 @ 2.10GHz 64 cores
Ram: 128GB
GPU: 4 x NVIDIA GeForce RTX 3090 24GB
1. Use Huggingface transformer to run the model
Nowaday most open model are released on Huggingface, a Github like platform for Large language model, they offer free space - a powerful and accessible platform that can greatly simplify the process of sharing, collaborating and testing model hosted on Huggingface. Qwen2 also published on HuggingFace, getting this model to run locally is simple, just follow general guideline and copy paste code from Transformers document.
I first try with Qwen2-7B-Instruct-GPTQ-Int8, because running bigger model is not possible, available hardware is not powerful, and 7B is big enough to do normal inference
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
model_name = "model/Qwen2-7B-Instruct-GPTQ-Int8"
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Describe a cat and tell a funny cat story"
messages = [
{"role": "system", "content": "You are lazycat, a helpful assistant"},
{"role": "user", "content": prompt}
]
start = time.time()
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print("Total processing time ", time.time() - start)
print(response)
Result is not good, model took around 2 minutes to respond with small and simple prompt
Total processing time 116.88880515098572
A cat, often a charming and enigmatic creature, is a common household companion across the globe. Cats, belonging to the family Felidae, typically possess a slender, agile body, a small head with large, expressive eyes, and a flexible spine that allows for exceptional agility. Their coats come in various colors and patterns, and they often possess a tuft of fur at the end of their tails. Cats have sharp claws and teeth, which they use for grooming themselves or hunting prey.
Now, let me share a funny cat story:
Once upon a time, there was a curious little kitten named Whiskers who lived in a cozy house with an elderly couple named Mr. and Mrs. Johnson. Whiskers was a tiny, playful feline with an endless curiosity about the world around him. One sunny afternoon, while the Johnsons were busy in the kitchen preparing lunch, Whiskers decided it was time for an adventure outside.
...
With this speed, it will not helpful in most case even if we want to build application for offline usage. Nvidia invents Int4 Precision for AI Inference which offers additional 59% Speedup Compared to INT8 model. In addition to computational speedups, using INT4 can also reduce a network’s memory footprint and conserve memory bandwidth, which makes it easier to run multiple ensemble networks on a single GPU. Qwen2 also release 7B-Int4 instruct model. Let's give it a try:
Total processing time 102.43286490440369
A cat is a small, typically furry, carnivorous mammal. They are often kept as pets due to their affectionate nature and playful behavior. Cats can vary greatly in size, shape, color, and patterns, but they all share certain characteristics that define them as felines:
1. **Body Structure**: Cats have a slender, agile body that allows them to jump great heights and distances. Their legs are muscular and allow for powerful leaps and quick movements. They also have retractable claws which help with climbing, hunting, and self-defense.
2. **Appearance**: The appearance of cats can range widely from short-haired breeds like Siamese or Persian cats to long-haired breeds such as Maine Coon or Turkish Van. They often have soft, silky fur that can come in various colors and patterns. Cats usually have large eyes with pupils that can expand widely, giving them excellent night vision.
3. **Temperament**: Cats are known for their independent nature, often seen lounging or sleeping throughout the day. They can be quite playful and curious, chasing after toys and exploring their surroundings. Some cats are more affectionate than others, seeking out human attention, while some prefer to keep a bit of distance.
4. **Habits**: Cats are known for their love of scratching, which helps them maintain the health of their claws and mark territory. They also enjoy grooming themselves, spending hours licking their fur to keep it clean and shiny.
Now, let's tell a funny cat story:
.....
Time to load and run this model is much faster than Int8, response time is improved but not really as expectation, it's still 102 seconds for a simple prompt. How about smaller model, example 1.5B parameters:
Total processing time 37.67355823516846
A cat is a small carnivorous mammal that is commonly kept as an animal of company. Cats are known for their independent nature and can be quite independent and aloof at times.
Here's a funny cat story:
....
With this speed, it will not helpful in most case even if we want to build application for offline usage. Nvidia invents Int4 Precision for AI Inference which offers additional 59% Speedup Compared to INT8 model. In addition to computational speedups, using INT4 can also reduce a network’s memory footprint and conserve memory bandwidth, which makes it easier to run multiple ensemble networks on a single GPU. Qwen2 also release 7B-Int4 instruct model. Let’s give it a try:
Total processing time 102.43286490440369
A cat is a small, typically furry, carnivorous mammal. They are often kept as pets due to their affectionate nature and playful behavior. Cats can vary greatly in size, shape, color, and patterns, but they all share certain characteristics that define them as felines:
1. **Body Structure**: Cats have a slender, agile body that allows them to jump great heights and distances. Their legs are muscular and allow for powerful leaps and quick movements. They also have retractable claws which help with climbing, hunting, and self-defense.
2. **Appearance**: The appearance of cats can range widely from short-haired breeds like Siamese or Persian cats to long-haired breeds such as Maine Coon or Turkish Van. They often have soft, silky fur that can come in various colors and patterns. Cats usually have large eyes with pupils that can expand widely, giving them excellent night vision.
3. **Temperament**: Cats are known for their independent nature, often seen lounging or sleeping throughout the day. They can be quite playful and curious, chasing after toys and exploring their surroundings. Some cats are more affectionate than others, seeking out human attention, while some prefer to keep a bit of distance.
4. **Habits**: Cats are known for their love of scratching, which helps them maintain the health of their claws and mark territory. They also enjoy grooming themselves, spending hours licking their fur to keep it clean and shiny.
Now, let's tell a funny cat story:
.....
Time to load and run this model is much faster than Int8, response time is improved but not really as expectation, it’s still 102 seconds for a simple prompt. How about smaller model, example 1.5B parameters:
Total processing time 37.67355823516846
A cat is a small carnivorous mammal that is commonly kept as an animal of company. Cats are known for their independent nature and can be quite independent and aloof at times.
Here's a funny cat story:
....
Turn out even with small model, improvement on speed is not so different since last year. So how can we improve speed?
2. vLLM
When searching around, I happen to read about vLLM which address the same issue we are facing with promising benchmark result as showed bellow:
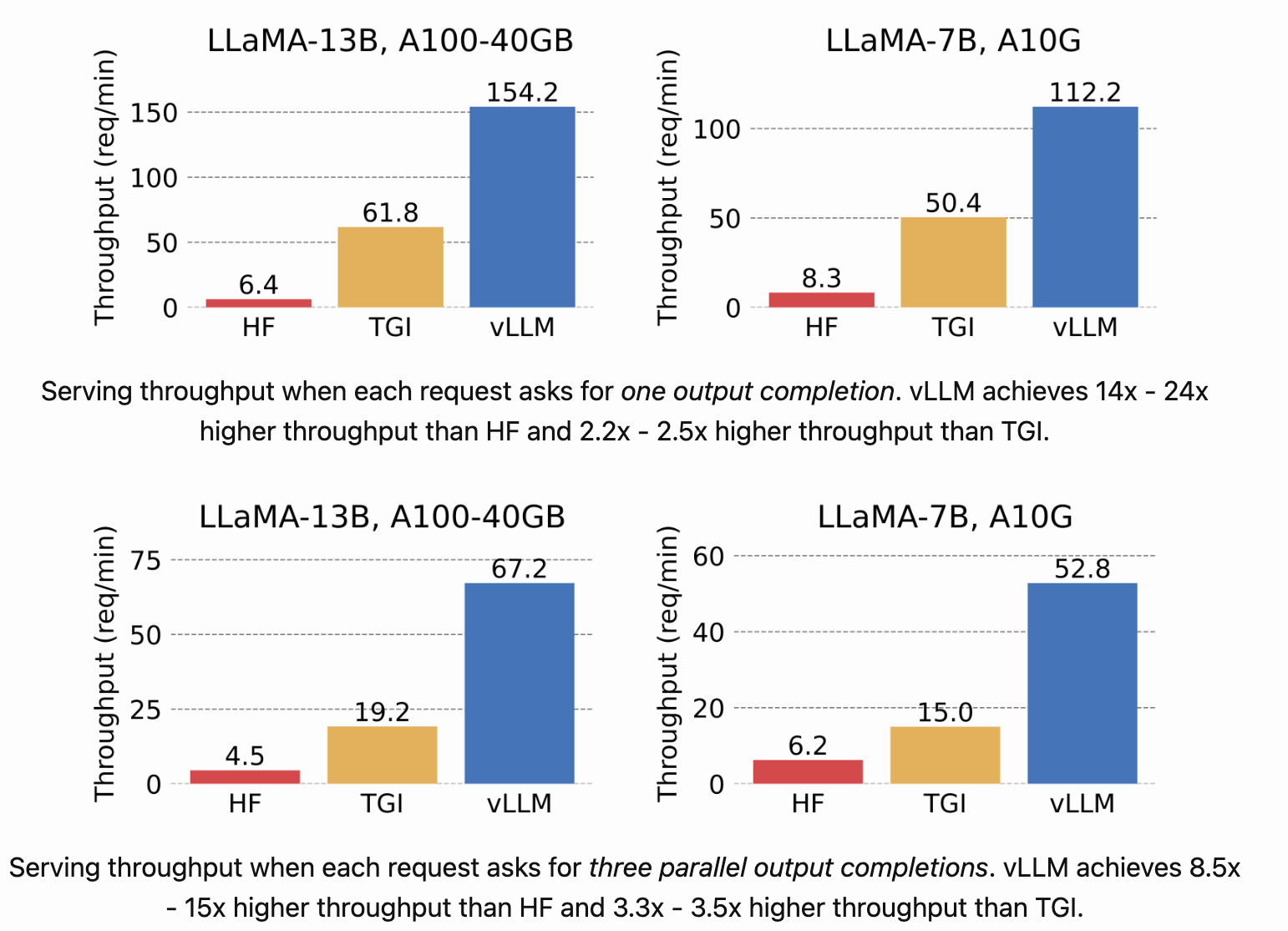
According to benchmark, vLLM offers 15x higher throughput than Huggingface’s transformers run on the same hardware. And the good thing is getting vLLM running is even easier than Transformers. It also offer ready to use set of OpenAI API. Let run same models with vLLM to see result in practice
Run vLLM with Qwen2-7B-Instruct-GPTQ-Int4 model
(vfin-advisor) hungnv4@ais-3090-test:/data/vfin-advisor$ python -m vllm.entrypoints.openai.api_server --host 127.0.0.1 --port 8081 --model /data/fin-advisor/model/Qwen2-7B-Instruct-GPTQ-Int4
Use OpenAI API with same prompt we tested with HuggingFace Transformer
from openai import OpenAI
import time
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8081/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
start = time.time()
cache = {}
prompt = "Describe a cat and tell a funny cat story"
chat_response = client.chat.completions.create(
model="/data/fin-advisor/model/Qwen2-7B-Instruct-GPTQ-Int4",
messages=[
{"role": "system", "content": "You are Toro, a helpful assistant"},
{"role": "user", "content": prompt},
]
)
print("Total processing time", time.time() - start)
print("Chat response:", chat_response.choices[0].message.content)
And result
(vfin-advisor) hungnv4@ais-3090-test:/data/vfin-advisor$ time python evaluate_llm.py
Total processing time 1.109113454818726
Chat response: A cat is a small, often agile, carnivorous mammal, which is considered a domesticated species and is one of the most widely kept pets globally. Cats are known for their independent nature, engaging personalities, and their ability to hunt small rodents and insects. They can communicate through various sounds, including purring, hissing, and meowing, and they are known for their sharp retractable claws and teeth, which they use for hunting and self-defense.
As for a funny cat story, I'll share one that always brings a smile:
**The Adventure of Spot and the Sock**
....
It’s 116x faster than Huggingface Transformer, other than that it’s easier to use and offer more flexible way to build application
3. Build an application
Fintech applications usually have a feature that summarizes user spending and earning based on transaction history. With this information, we can build an application to leverage the API to consume spending’s history of user, then recommend user to explore other usecases, example:
- Manage bill more efficiency
- Use MMF as a way to save money
- Start using stock to invest in company they like
- Watch movie during weekend, etc
Application flow:
- Use public API to collect spending history
- Use response from this API as input prompt
- Recommend usage based on our available services Without a lot of code, our POC:
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8081/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
import requests
from starlette.requests import Request
from starlette.responses import Response
from typing import Dict
from dateutil.tz import UTC
import datetime
from functools import lru_cache, wraps
from ray import serve
# remove un-necessary fields
keys_to_remove = ('icon', 'background')
def remove_garbage(obj):
data = []
for item in obj:
data.append({key : value for key, value in item.items() if key not in keys_to_remove})
return data
def clean_data(history):
clear_history = {}
spending = remove_garbage(history['spending'])
earning = remove_garbage(history['earning'])
clear_history['spending'] = spending
clear_history['earning'] = earning
return clear_history
# a local cache
def timed_lru_cache(seconds: int, maxsize: int = 128):
def wrapper_cache(func):
func = lru_cache(maxsize=maxsize)(func)
func.lifetime = datetime.timedelta(seconds=seconds)
func.expiration = datetime.datetime.now(UTC) + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
if datetime.datetime.now(UTC) >= func.expiration:
func.cache_clear()
func.expiration = datetime.datetime.now(UTC) + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
# Only respond with JSON with 3 fields, "recommendation", "service", "link" for each service. The value of "recommendation" field should be in Vietnamese.
system_prompt = """
You are Lazycat, a helpful financial assistant. Given our application has following services as json string
{
{
"service": "Thanh toán hoá đơn",
"link": 'lazycat://bill',
"description": "Là dịch vụ thanh toán các loại hóa đơn sau: Điện, Nước, Internet, Truyền hình, Điện thoại cố định/ myTV của VNPT, Đi động trả sau, Vay tiêu dùng, Phí bảo hiểm, Chi phí chung cư."
},
{
"service": "Điện thoại",
"link": "lazycat://telco"
"description": "Dịch vụ Nạp tiền điện thoại cho thuê bao di động trả trước của tất cả các mạng viễn thông tại Việt Nam.
Thanh toán cước cho thuê bao di động trả sau.
Mua thẻ cào điện thoại của các mạng viễn thông Viettel, MobiFone, VinaPhone.
Mua thẻ game của các nhà cung cấp dịch vụ như FPT, VNG, VTC…
Nạp tiền vào ví điện tử để thanh toán dịch vụ và mua hàng "
},
{
"service": "Số dư sinh lời",
"link": "lazycat://invest",
"description": "Dịch vụ giúp Sinh lời 4.2% từ khoản chi tiêu hằng tháng, Thanh toán được tất cả dịch vụ và các cửa hàng chấp nhận thanh toán qua Lazycat trên toàn quốc "
},
{
"service": "Đầu tư chứng khoán",
"link": "lazycat://stock",
"description": " Dịch vụ cho phép TRẢI NGHIỆM ĐẦU TƯ CHỈ TỪ 1 CỔ PHIẾU ngay trên Lazycat. Tài khoản chứng khoán giúp bạn bắt đầu hành trình đầu tư một cách đơn giản và an toàn. Trực tiếp sở hữu công ty bạn yêu thích từ số vốn nhỏ"
}
}
When provide recommendation, please give output as JSON string with service and service link provided in JSON above so user can open recommended service to use.
Recommend 2 to 3 services, include recommendation as json properties within output json to describe clearly why it's recommended.
Only recommend available services in above description, do not make up the answer.
Json response must follow following format, "summarization" and "recommendation" MUST be in Vietnamese:
[
"summarization" : "",
"recommendations": [
{
"recommendation": "Dựa trên thói quen chi tiêu của bạn, việc sử dụng dịch vụ 'Số dư sinh lời' có thể giúp tối ưu hóa thu nhập của bạn. Ngoài ra, 'Đầu tư chứng khoán' có thể là lựa chọn tốt nếu bạn muốn mở rộng cơ hội đầu tư.",
"service": "Số dư sinh lời",
"link": "lazycat://invest"
},
{
"recommendation": "Dựa trên thói quen chi tiêu của bạn, việc sử dụng dịch vụ 'Đầu tư chứng khoán' có thể giúp bạn bắt đầu hành trình đầu tư một cách đơn giản và an toàn.",
"service": "Đầu tư chứng khoán",
"link": "lazycat://stock"
},
...
]
]
"""
user_prompt_template = """
Given spending history of user as following, please give recommendation
{}
"""
spending_api = "https://sapi.lazycat.vn/v1/pfm/summary/category?filter_month=2024-07"
def recommendation(input : str):
promt = user_prompt_template.format(input)
chat_response = client.chat.completions.create(
model="/data/fin-advisor/model/Qwen2-7B-Instruct-GPTQ-Int4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": promt},
]
)
return chat_response.choices[0].message.content
def retrieve_spending_history(token: str):
token = "token={}".format(token)
response = requests.get(spending_api, headers={"cookie" : token})
return response.json()
# we do not want to respond different result everytime user makes request
# we want to save computing power to serve other user
# so apply the cache
@timed_lru_cache(seconds=24*60*60, maxsize=1000000)
def seek_recommendation(token: str):
spending_history = retrieve_spending_history(token)
return recommendation(clean_data(spending_history))
error_response = """
<p> There's no information about you, please visit lazycat's home and login using below link first, then refresh this page. </p>
<a href="https://home.lazycat.vn" target="_blank">Let lazycat identify you</a>
"""
@serve.deployment
class Assistant:
# def __init__(self):
# self._msg = msg
async def __call__(self, request: Request) -> Dict:
try:
cookie = request.cookies.get('zlp_token')
if cookie is None or len(cookie) == 0:
return Response(error_response, media_type = 'text/html')
return Response(seek_recommendation(cookie), media_type = 'application/json' )
except Exception:
return "we are having an error, that's all we know. Please comeback later."
app = Assistant.bind()
Run the server:
(vfin-advisor) hungnv4@ais-3090-test:/data/vfin-advisor$ serve run serve_config.yaml
See example recommendation based on my spending history with in August
[
"summarization" : "Bạn đã chi trả khá nhiều cho các dịch vụ ăn uống, mua sắm nhu yếu phẩm trong tháng 8 nhưng chưa thực sự quan tâm đến đầu tư, sinh lời",
"recommendations": [
{
"recommendation": "Dựa trên thói quen chi tiêu của bạn, việc sử dụng dịch vụ 'Số dư sinh lời' có thể giúp tối ưu hóa thu nhập của bạn. Số dư này giúp sinh lời 4.2% từ số tiền bạn dùng để thực hiện giao dịch trong lúc nhàn rỗi, bạn vẫn có thể thanh toán mọi dịch vụ từ số dư này",
"service": "Số dư sinh lời",
"link": "lazycat://invest"
},
{
"recommendation": "Bạn cũng có thể trải nghiệm việc đầu tư chứng khoán từ 1 cổ phiếu để làm quen với việc đầu tư và thị trường chứng khoán",
"service": "Đầu tư chứng khoán",
"link": "lazycat://stock"
}
]
]
4. Performance test
To evaluate performance, we need to do a simple performance benchmark. We will try to increase number of concurrency to to know how fast this methodology is.
from openai import OpenAI
from threading import Thread
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8081/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
cache = {}
system_prompt = """
...
"""
user_prompt = """
...
"""
import time
time_spent = []
def generate(start: float):
_ = client.chat.completions.create(
model="/data/fin-advisor/model/Qwen2-7B-Instruct-GPTQ-Int4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
)
time_spent.append(time.time() - start)
if __name__ == '__main__':
import sys
thread_numbers = 5 if len(sys.argv) < 2 else int(sys.argv[1])
# thread_numbers = 5 if thread_numbers is None or len(thread_numbers) == 0 else int(thread_numbers)
threads = []
for i in range(thread_numbers):
t = Thread(target=generate, args=(time.time(),))
threads.append(t)
t.start()
for thread in threads:
thread.join()
print("average time spent each inferrence", sum(time_spent) / thread_numbers)
To do concurrency test, we will use python bench.py numer_of_thread. Example:
(vfin-advisor) hungnv4@ais-3090-test:/data/vfin-advisor$ python bench.py 1
average time spent each inferrence 2.54970121383667
One GPU result:
| concurrency | average time spent (second) |
|---|---|
| 1 | 2.3 |
| 5 | 5.1 |
| 10 | 8.4 |
| 20 | 14.1 |
Vllm have option to utilize multiple GPUs, since our server has 4 GPU, let give it a try:
(vfin-advisor) hungnv4@ais-3090-test:/data/vfin-advisor$ python -m vllm.entrypoints.openai.api_server --host 127.0.0.1 --port 8081 --tensor-parallel-size 4 --model /data/fin-advisor/model/Qwen2-7B-Instruct-GPTQ-Int4
4 GPUs result:
| concurrency | average time spent (second) |
|---|---|
| 1 | 1.1 |
| 5 | 3.21 |
| 10 | 4.95 |
| 20 | 6.48 |
It’s much better when using multiple GPU. Next step, we will try to apply RAG to reduce context length.
5. RAG
Why applying RAG will reduce context and prompt length? If you take look at our original POC, available services are embedded into user’s prompt so we can tell LLM to use these services to recommend user after analyzing user spending history. Imagine if we have hundreds or thousands of service, our prompt will take forever to process.
To be more detail, with current hardware and 7B model, the best performance we can process is around 200 tokens/s. What does it mean by token/s? A token is a unit that LLM model will process, lets say if our prompt is “Tell me about Lazycat”, and we implement a simple tokenization method to split prompt into word array, it will become [“Tell”, “me”, “about”, “Lazycat”], each word in that array is a token. Certainly in real world, people will represent tokenized text as vectors, and there is a process involves taking each token and converting it into vector using some special internal model’s representation will be more effective. If you want to learn more about tokenization, please read Andrej Karpathy project: Minimal, clean code for the Byte Pair Encoding (BPE) algorithm commonly used in LLM tokenization and search Google to teach yourself about BPE, GPT-* tokenizer.
Other than prompt length, we know that LLM can understand human language, but its knowledge is limit by trained data cutoff date. Example, if you ask any LLM to tell you about your new career update on Linkedin, all answer if any will be a lie or mis-information. We can use RAG to embed latest, structured information to provide better context to our use case:
- It helps shorten prompt
- It provides latest information
- It prevents mis-information
- It decouples data preparation and LLM processing
5.1 How to use RAG
To build a RAG application, basically we will implement 2 steps:
- Embedding our latest data into a vector database. In our example, we tokenize our available services and store tokenized data into a database, which later we can search using that database. If you are new into this, this basically building simple search based on semantic instead of regular expression, text similarity, etc.
- When building prompt, instead of bundling all data into it, we 1) tokenize user spending history 2) perform a search into vector database to get result 3) use that result as context in prompt query.
You may already learn and apply RAG easily through ton of Internet resource, but there’s one thing people may not tell you, to get RAG works well, what you really need is a good Tokenizer. Without a good tokenizer, no matter how good is dataset, your context will be very different from user question
5.2 Re-work our POC
As mentioned, we will have to build a vector database to store our available services. To do this, we will need to have an embedding model to tokenize data into vector presentation, in this case I use all-mpnet-base-v2, simply because it supports Vietnamese. Code below explains itself
# load the model
model = SentenceTransformer("/data/fin-advisor/model/tokenizer/all-mpnet-base-v2")
# our data
available_services = """
[
{
"service": "Thanh toán hoá đơn",
"link": "lazycat://bill",
"description": "Là dịch vụ thanh toán các loại hóa đơn sau: Điện, Nước, Internet, Truyền hình, Điện thoại cố định/ myTV của VNPT, Đi động trả sau, Vay tiêu dùng, Phí bảo hiểm, Chi phí chung cư."
},
{
"service": "Điện thoại",
"link": "lazycat://telco",
"description": "Dịch vụ Nạp tiền điện thoại cho thuê bao di động trả trước của tất cả các mạng viễn thông tại Việt Nam. Thanh toán cước cho thuê bao di động trả sau."
},
{
"service": "Số dư sinh lời",
"link": "lazycat://invest",
"description": "Dịch vụ giúp Sinh lời 4.2% từ khoản chi tiêu hằng tháng, Thanh toán được tất cả dịch vụ và các cửa hàng chấp nhận thanh toán qua Lazycat trên toàn quốc "
},
{
"service": "Đầu tư chứng khoán",
"link": "lazycat://stock",
"description": " Dịch vụ cho phép TRẢI NGHIỆM ĐẦU TƯ CHỈ TỪ 1 CỔ PHIẾU - NGAY TRÊN Lazycat. Tài khoản chứng khoán giúp bạn bắt đầu hành trình đầu tư một cách đơn giản và an toàn. Trực tiếp sở hữu công ty bạn yêu thích từ số vốn nhỏ"
}
]
"""
services = json.loads(available_services)
# tokenize and embedding
embeddings = model.encode(services, show_progress_bar=True)
faiss_index = faiss.IndexFlatIP(model.get_sentence_embedding_dimension())
faiss_index.add(embeddings)
Next step, we revamp our original prompt into a shorter version:
base_prompt = """
You are Lazycat, a helpful financial assistant. Given Lazycat has following services as json string. When provide recommendation, you MUST give output as array of JSON string with "service", "description", "link", "summarization" and "recommendation" properties using information provided context so user can open recommended service to use.
"summarization" and "recommendation", "description" MUST be in Vietnamese
Recommend 2 to 3 services, the "description" json properties within output json to describe clearly why it's recommended.
Your answers are correct, high-quality, and written by an domain expert. Only recommend available services in provided context, do not make up the answer.
User Question: {}
Contexts:
{}
"""
You can see we have “User Question” and “Contexts” to be filled later. User Question is dynamic data we need the LLM to evaluate, the dynamic data is user’s spending history. On the other hand “Contexts” is the search result returned when we perform search query using tokenized “User Question” into database we built. Example with “User Question”:
{
"earning": [
{
"name": "Nhận tiền",
"amount": "3000",
"count": "2",
}
],
"spending": [
{
"name": "Dịch vụ khác",
"amount": "210000",
"count": "4",
},
{
"name": "Vận chuyển & Giao hàng",
"amount": "63000",
"count": "2",
},
{
"name": "Dịch vụ viễn thông",
"amount": "58000",
"count": "5",
},
{
"name": "Ăn uống",
"amount": "45000",
"count": "1",
},
{
"name": "Mua sắm",
"amount": "35000",
"count": "1",
},
{
"name": "Chuyển tiền vào Số dư sinh lời",
"amount": "2000",
"count": "1",
},
{
"name": "Chuyển tiền",
"amount": "1000",
"count": "1",
}
]
}
Lets see how we perform the search:
# number of search result should be returned
k = 5
# tokenize the user question
query_embedding = model.encode([question])
# Search
_, indices = faiss_index.search(query_embedding, k)
context = "\n".join([f"{i}. {services[index]}" for i, index in enumerate(indices[0])])
At this step we have both “User Question” and “Contexts”, we then build our completed prompt from base prompt and query the LLM
prompt = f"{base_prompt.format(question, context)}"
response = client.chat.completions.create(
model="/data/fin-advisor/model/Qwen2-7B-Instruct-GPTQ-Int4",
messages=[
{"role": "system", "content": prompt},
]
)
And result:
(vfin-advisor) hungnv4@ais-3090-test:/data/vfin-advisor$ python tokenizer_test.py 1
Batches: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 6.05it/s]
Chat response: [
{
"service": "Thanh toán hoá đơn",
"description": "Đây là dịch vụ thanh toán các loại hóa đơn sau: Điện, Nước, Internet, Truyền hình, Điện thoại cố định/ myTV của VNPT, Đi động trả sau, Vay tiêu dùng, Phí bảo hiểm, Chi phí chung cư.",
"link": "lazycat://bill",
"recommendation": "Bạn đang tiêu lớn cho các dịch vụ vận chuyển và giao hàng. Việc thanh toán các hóa đơn hàng tháng như điện, nước, internet, và dịch vụ viễn thông sẽ giúp bạn giảm chi tiêu và quản lý tài chính tốt hơn."
},
{
"service": "Đầu tư chứng khoán",
"description": "Dịch vụ cho phép TRẢI NGHIỆM ĐẦU TƯ CHỈ TỪ 1 CỔ PHIẾU - NGAY TRÊN Lazycat. Tài khoản chứng khoán giúp bạn bắt đầu hành trình đầu tư một cách đơn giản và an toàn. Trực tiếp sở hữu công ty bạn yêu thích từ số vốn nhỏ.",
"link": "lazycat://stock",
"recommendation": "Nếu bạn đã bắt đầu có một số thu nhập từ việc nhận tiền và có tiền tiết kiệm, đầu tư chứng khoán có thể là một lựa chọn tốt để tăng thêm thu nhập. Dịch vụ này giúp bạn bắt đầu hành trình đầu tư một cách đơn giản và an toàn."
}
]
6. Fine tune a model
We can also finetune LLM model to use for our customized task, or our specific domain or application usecase. Other than that, in case we want to reduce unwanted response, ie sometimes prompt engineering won’t work as we expect, fine-tuning may help filter out irrelevant, inappropriate, or unhelpful responses by tailoring the model to exclude certain topics or types of content
In this post, I will present a way to use public data to build dataset and finetune the model.
6.1. Prepare dataset
We get data from Zalopay faq https://zalopay.vn/hoi-dap/quan-ly-tai-khoan/khoa-mo-khoa-tai-khoan. This contains 3 category of data:
- Zalopay features
- Frequent asked questions and answer
- Some unstructured data
For unstructured data, you can also use LLMs to construct question and answer just by prompt engineering, as following:
prompt = """
Given following json string
{}
Construct a new json item with only "question" and "answer" attributes using context given by that string.
Remember this context is about Zalopay - a financial platform which provide solution for user to pay for their orders.
You only respond json result, do not provide anything else. The question and answer must be in Vietnamese. Remove tab, linebreak character in your answer if any, make sure your response is perfectly json formatted.
"""
However, I won’t go into detail, will leave it as an exercise for reader. To prepare dataset from Zalopay FAQ, we can use following script:
data_set = []
import re
import urllib
def clean_html_tags(text):
clean = re.compile('<.*?>')
return re.sub(clean, '', text)
def retrieve(url: str):
response = urllib.request.urlopen(url)
return json.loads(response.read())
def instruction(k: str, v: str) -> str:
data = {}
k = clean_html_tags(k)
v = clean_html_tags(v)
# print(v)
data["instruction"] = k
data["answer"] = v
return json.dumps(data, ensure_ascii=False)
def get_faq():
faq_url = "https://zalopay.vn/_next/data/hYsnP2id3F00kMlCQOFJI/vi/hoi-dap.json"
response = retrieve(faq_url)
articles = response["pageProps"]["data"]["articles"]
for article in articles:
data_set.append(instruction( article["title"], article["description_text"]))
def get_features():
features_url = "https://zalopay.vn/_next/data/hYsnP2id3F00kMlCQOFJI/vi.json"
response = retrieve(features_url)
# print(response)
items = response["pageProps"]["items"]
for o in items:
try:
if o["__component"] == "shared.promote-points":
data_set.append(instruction( o["title"], o["description"]))
if o["__component"] == "shared.bank-list":
data_set.append(instruction( o["title"], o["description"]))
if "left_items" in o:
for item in o["left_items"]:
data_set.append(instruction( item["title"], item["description"]))
if "right_items" in o:
for item in o["right_items"]:
data_set.append(instruction( item["title"], item["description"]))
if "items" in o:
for item in o["items"]:
data_set.append(instruction( item["title"], item["description"]))
if "merchants" in o:
for item in o["merchants"]:
data_set.append(instruction( item["merchant"]["title"], item["merchant"]["description"]))
if "banks" in o:
for item in o["banks"]:
data_set.append(instruction( item["bank"]["title"], "Liên kết tài khoản hoặc thẻ ngân hàng {} với Zalopay một cách dễ dàng".format(item["bank"]["title"]) ))
except Exception:
continue
From this, we will have around 1000+ data sample. We then build a chatml chat message template to prepare dataset to finetune the LLM model, the message has following format:
{
"type": "chatml",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Tell me something about large language models."
},
{
"role": "assistant",
"content": "Large language models are a type of language model that is trained on a large corpus of text data. They are capable of generating human-like text and are used in a variety of natural language processing tasks..."
}
],
"source": "unknown"
}
Write another script to gen template
for line in data_set:
data_item = json.loads(line)
item = {"type": "chatml"}
system_message_content = "You are Toro, a helpful assistant. Your answers are correct, high-quality, and written by an domain expert"
system_role = "system"
user_message_content = data_item["instruction"]
user_role = "user"
assistant_message_content = data_item["answer"]
assistant_role = "assistant"
item["source"] = "unknown"
message = []
message.append({"role": system_role, "content": system_message_content})
message.append({"role": user_role, "content": user_message_content})
message.append({"role": assistant_role, "content": assistant_message_content})
item["messages"] = message
jsonl_array.append(item)
Sample data:
{
"type": "chatml",
"source": "unknown",
"messages": [
{
"role": "system",
"content": "You are Toro, a helpful assistant. Your answers are correct, high-quality, and written by an domain expert"
},
{
"role": "user",
"content": "ZALOPAY - ỨNG DỤNG THANH TOÁN TÍCH THƯỞNG"
},
{
"role": "assistant",
"content": "Ứng dụng thanh toán Zalopay chính thức ra mắt phiên bản mới với các thay đổi hấp dẫn, làm mới mọi trải nghiệm về tiền."
}
]
}
6.2. Finetune
We will apply Lora when doing finetuning, some of my reasons:
- We have to use 7B model since it’s more accurate and provide better quality answer compared with 1.5B model
- Lora provides a practical and efficient approach to fine-tuning LLMs, balancing the need for model adaptability with computational and resource constraints, ie it saves memory, we do not have H100 or A100 GPU server to finetune model. In this experiment, if we do not use Lora, we will be out-of-memory
6.2.1 Lora with SFT trainer
I grab a SFT finetune version from tatsu-lab/stanford_alpaca and modify a bit
# This code is based on the revised code from fastchat based on tatsu-lab/stanford_alpaca.
import json
import logging
import os
import pathlib
from dataclasses import dataclass, field
from typing import Dict, List, Optional
import torch
import transformers
from accelerate.utils import DistributedType
from deepspeed import zero
from deepspeed.runtime.zero.partition_parameters import ZeroParamStatus
from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from torch.utils.data import Dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
Trainer,
deepspeed,
)
from transformers.trainer_pt_utils import LabelSmoother
IGNORE_TOKEN_ID = LabelSmoother.ignore_index
TEMPLATE = "{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content']}}{% if loop.last %}{{ '<|im_end|>'}}{% else %}{{ '<|im_end|>\n' }}{% endif %}{% endfor %}"
local_rank = None
def rank0_print(*args):
if local_rank == 0:
print(*args)
@dataclass
class ModelArguments:
model_name_or_path: Optional[str] = field(default="Qwen/Qwen2-7B")
@dataclass
class DataArguments:
data_path: str = field(
default=None, metadata={"help": "Path to the training data."}
)
eval_data_path: str = field(
default=None, metadata={"help": "Path to the evaluation data."}
)
lazy_preprocess: bool = False
@dataclass
class TrainingArguments(transformers.TrainingArguments):
cache_dir: Optional[str] = field(default=None)
optim: str = field(default="adamw_torch")
model_max_length: int = field(
default=8192,
metadata={
"help": "Maximum sequence length. Sequences will be right padded (and possibly truncated)."
},
)
use_lora: bool = False
@dataclass
class LoraArguments:
lora_r: int = 64
lora_alpha: int = 16
lora_dropout: float = 0.05
lora_target_modules: List[str] = field(
default_factory=lambda: [
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"up_proj",
"gate_proj",
"down_proj",
]
)
lora_weight_path: str = ""
lora_bias: str = "none"
q_lora: bool = False
def maybe_zero_3(param):
if hasattr(param, "ds_id"):
assert param.ds_status == ZeroParamStatus.NOT_AVAILABLE
with zero.GatheredParameters([param]):
param = param.data.detach().cpu().clone()
else:
param = param.detach().cpu().clone()
return param
# Borrowed from peft.utils.get_peft_model_state_dict
def get_peft_state_maybe_zero_3(named_params, bias):
if bias == "none":
to_return = {k: t for k, t in named_params if "lora_" in k}
elif bias == "all":
to_return = {k: t for k, t in named_params if "lora_" in k or "bias" in k}
elif bias == "lora_only":
to_return = {}
maybe_lora_bias = {}
lora_bias_names = set()
for k, t in named_params:
if "lora_" in k:
to_return[k] = t
bias_name = k.split("lora_")[0] + "bias"
lora_bias_names.add(bias_name)
elif "bias" in k:
maybe_lora_bias[k] = t
for k, t in maybe_lora_bias:
if bias_name in lora_bias_names:
to_return[bias_name] = t
else:
raise NotImplementedError
to_return = {k: maybe_zero_3(v) for k, v in to_return.items()}
return to_return
def safe_save_model_for_hf_trainer(
trainer: transformers.Trainer, output_dir: str, bias="none"
):
"""Collects the state dict and dump to disk."""
# check if zero3 mode enabled
if deepspeed.is_deepspeed_zero3_enabled():
state_dict = trainer.model_wrapped._zero3_consolidated_16bit_state_dict()
else:
if trainer.args.use_lora:
state_dict = get_peft_state_maybe_zero_3(
trainer.model.named_parameters(), bias
)
else:
state_dict = trainer.model.state_dict()
if trainer.args.should_save and trainer.args.local_rank == 0:
trainer._save(output_dir, state_dict=state_dict)
def preprocess(
messages,
tokenizer: transformers.PreTrainedTokenizer,
max_len: int,
) -> Dict:
"""Preprocesses the data for supervised fine-tuning."""
texts = []
for i, msg in enumerate(messages):
texts.append(
tokenizer.apply_chat_template(
msg,
chat_template=TEMPLATE,
tokenize=True,
add_generation_prompt=False,
padding="max_length",
max_length=max_len,
truncation=True,
)
)
input_ids = torch.tensor(texts, dtype=torch.int)
target_ids = input_ids.clone()
target_ids[target_ids == tokenizer.pad_token_id] = IGNORE_TOKEN_ID
attention_mask = input_ids.ne(tokenizer.pad_token_id)
return dict(
input_ids=input_ids, target_ids=target_ids, attention_mask=attention_mask
)
class SupervisedDataset(Dataset):
"""Dataset for supervised fine-tuning."""
def __init__(
self, raw_data, tokenizer: transformers.PreTrainedTokenizer, max_len: int
):
super(SupervisedDataset, self).__init__()
rank0_print("Formatting inputs...")
messages = [example["messages"] for example in raw_data]
data_dict = preprocess(messages, tokenizer, max_len)
self.input_ids = data_dict["input_ids"]
self.target_ids = data_dict["target_ids"]
self.attention_mask = data_dict["attention_mask"]
def __len__(self):
return len(self.input_ids)
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
return dict(
input_ids=self.input_ids[i],
labels=self.target_ids[i],
attention_mask=self.attention_mask[i],
)
class LazySupervisedDataset(Dataset):
"""Dataset for supervised fine-tuning."""
def __init__(
self, raw_data, tokenizer: transformers.PreTrainedTokenizer, max_len: int
):
super(LazySupervisedDataset, self).__init__()
self.tokenizer = tokenizer
self.max_len = max_len
rank0_print("Formatting inputs...Skip in lazy mode")
self.tokenizer = tokenizer
self.raw_data = raw_data
self.cached_data_dict = {}
def __len__(self):
return len(self.raw_data)
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
if i in self.cached_data_dict:
return self.cached_data_dict[i]
ret = preprocess([self.raw_data[i]["messages"]], self.tokenizer, self.max_len)
ret = dict(
input_ids=ret["input_ids"][0],
labels=ret["target_ids"][0],
attention_mask=ret["attention_mask"][0],
)
self.cached_data_dict[i] = ret
return ret
def make_supervised_data_module(
tokenizer: transformers.PreTrainedTokenizer,
data_args,
max_len,
) -> Dict:
"""Make dataset and collator for supervised fine-tuning."""
dataset_cls = (
LazySupervisedDataset if data_args.lazy_preprocess else SupervisedDataset
)
rank0_print("Loading data...")
train_data = []
with open(data_args.data_path, "r") as f:
for line in f:
train_data.append(json.loads(line))
train_dataset = dataset_cls(train_data, tokenizer=tokenizer, max_len=max_len)
if data_args.eval_data_path:
eval_data = []
with open(data_args.eval_data_path, "r") as f:
for line in f:
eval_data.append(json.loads(line))
eval_dataset = dataset_cls(eval_data, tokenizer=tokenizer, max_len=max_len)
else:
eval_dataset = None
return dict(train_dataset=train_dataset, eval_dataset=eval_dataset)
def train():
global local_rank
parser = transformers.HfArgumentParser(
(ModelArguments, DataArguments, TrainingArguments, LoraArguments)
)
(
model_args,
data_args,
training_args,
lora_args,
) = parser.parse_args_into_dataclasses()
# This serves for single-gpu qlora.
if (
getattr(training_args, "deepspeed", None)
and int(os.environ.get("WORLD_SIZE", 1)) == 1
):
training_args.distributed_state.distributed_type = DistributedType.DEEPSPEED
local_rank = training_args.local_rank
device_map = None
world_size = int(os.environ.get("WORLD_SIZE", 1))
ddp = world_size != 1
if lora_args.q_lora:
device_map = {"": int(os.environ.get("LOCAL_RANK") or 0)} if ddp else "auto"
if len(training_args.fsdp) > 0 or deepspeed.is_deepspeed_zero3_enabled():
logging.warning("FSDP or ZeRO3 is incompatible with QLoRA.")
model_load_kwargs = {
"low_cpu_mem_usage": not deepspeed.is_deepspeed_zero3_enabled(),
}
compute_dtype = (
torch.float16
if training_args.fp16
else (torch.bfloat16 if training_args.bf16 else torch.float32)
)
# Load model and tokenizer
config = transformers.AutoConfig.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
)
config.use_cache = False
model = AutoModelForCausalLM.from_pretrained(
model_args.model_name_or_path,
config=config,
cache_dir=training_args.cache_dir,
device_map=device_map,
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
)
if training_args.use_lora and lora_args.q_lora
else None,
**model_load_kwargs,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
model_max_length=training_args.model_max_length,
padding_side="right",
use_fast=False,
)
if training_args.use_lora:
lora_config = LoraConfig(
r=lora_args.lora_r,
lora_alpha=lora_args.lora_alpha,
target_modules=lora_args.lora_target_modules,
lora_dropout=lora_args.lora_dropout,
bias=lora_args.lora_bias,
task_type="CAUSAL_LM",
# task_type="QUESTION_ANS"
)
if lora_args.q_lora:
model = prepare_model_for_kbit_training(
model, use_gradient_checkpointing=training_args.gradient_checkpointing
)
model = get_peft_model(model, lora_config)
# Print peft trainable params
model.print_trainable_parameters()
if training_args.gradient_checkpointing:
model.enable_input_require_grads()
# Load data
data_module = make_supervised_data_module(
tokenizer=tokenizer, data_args=data_args, max_len=training_args.model_max_length
)
# Start trainer
trainer = Trainer(
model=model, tokenizer=tokenizer, args=training_args, **data_module
)
# `not training_args.use_lora` is a temporary workaround for the issue that there are problems with
# loading the checkpoint when using LoRA with DeepSpeed.
# Check this issue https://github.com/huggingface/peft/issues/746 for more information.
if (
list(pathlib.Path(training_args.output_dir).glob("checkpoint-*"))
and not training_args.use_lora
):
trainer.train(resume_from_checkpoint=True)
else:
trainer.train()
trainer.save_state()
safe_save_model_for_hf_trainer(
trainer=trainer, output_dir=training_args.output_dir, bias=lora_args.lora_bias
)
if __name__ == "__main__":
train()
Since above finetune code relied heavily on torch, following bash script I also got from tatsu-lab/stanford_alpaca, use it to launch our finetune job
#!/bin/bash
export CUDA_DEVICE_MAX_CONNECTIONS=1
# Guide:
# This script supports distributed training on multi-gpu workers (as well as single-worker training).
# Please set the options below according to the comments.
# For multi-gpu workers training, these options should be manually set for each worker.
# After setting the options, please run the script on each worker.
# Number of GPUs per GPU worker
GPUS_PER_NODE=$(python -c 'import torch; print(torch.cuda.device_count())')
# Number of GPU workers, for single-worker training, please set to 1
NNODES=${NNODES:-1}
# The rank of this worker, should be in {0, ..., WORKER_CNT-1}, for single-worker training, please set to 0
NODE_RANK=${NODE_RANK:-0}
# The ip address of the rank-0 worker, for single-worker training, please set to localhost
MASTER_ADDR=${MASTER_ADDR:-localhost}
# The port for communication
MASTER_PORT=${MASTER_PORT:-6001}
MODEL="Qwen/Qwen2-7B" # Set the path if you do not want to load from huggingface directly
# ATTENTION: specify the path to your training data, which should be a json file consisting of a list of conversations.
# See https://qwen.readthedocs.io/en/latest/training/SFT/example.html#data-preparation for more information.
DATA="example_data.jsonl"
DS_CONFIG_PATH="ds_config_zero3.json"
USE_LORA=False
Q_LORA=False
function usage() {
echo '
Usage: bash finetune.sh [-m MODEL_PATH] [-d DATA_PATH] [--deepspeed DS_CONFIG_PATH] [--use_lora USE_LORA] [--q_lora Q_LORA]
'
}
while [[ "$1" != "" ]]; do
case $1 in
-m | --model )
shift
MODEL=$1
;;
-d | --data )
shift
DATA=$1
;;
--deepspeed )
shift
DS_CONFIG_PATH=$1
;;
--use_lora )
shift
USE_LORA=$1
;;
--q_lora )
shift
Q_LORA=$1
;;
-h | --help )
usage
exit 0
;;
* )
echo "Unknown argument ${1}"
exit 1
;;
esac
shift
done
DISTRIBUTED_ARGS="
--nproc_per_node $GPUS_PER_NODE \
--nnodes $NNODES \
--node_rank $NODE_RANK \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT
"
torchrun $DISTRIBUTED_ARGS finetune.py \
--model_name_or_path $MODEL \
--data_path $DATA \
--bf16 True \
--output_dir output_qwen \
--num_train_epochs 5 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 10 \
--save_total_limit 10 \
--learning_rate 3e-4 \
--weight_decay 0.01 \
--adam_beta2 0.95 \
--warmup_ratio 0.01 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "none" \
--model_max_length 512 \
--lazy_preprocess True \
--use_lora ${USE_LORA} \
--q_lora ${Q_LORA} \
--gradient_checkpointing \
--deepspeed ${DS_CONFIG_PATH}
We also need to define a configuration file for the job:
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "none",
"pin_memory": true
},
"offload_param": {
"device": "none",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 100,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
Finetune the model, this took around 1 hour to finish
bash finetune.sh -m /data/fin-advisor/model/Qwen2-7B-Instruct -d data.jsonl --use_lora True
6.2.2 Lora with Usloth
usloth can finetune model applying Lora (https://github.com/unslothai/unsloth) since it helps finetuning model with less required memory, and result better speed, the only limitation is it only support single GPU training. Code to train is as following:
from unsloth import FastLanguageModel
import torch
import json
from datasets import load_from_disk, load_dataset
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
max_seq_length = 2048
dtype = None
load_in_4bit = True
fourbit_models = [
"/data/fin-advisor/model/Qwen2-7B-Instruct",
]
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "/data/fin-advisor/model/Qwen2-7B-Instruct",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
zalopay_prompt = """
### Instruction:
You are Toro, a helpful Zalopay assistant.
Your answers are correct, high-quality, and written by Zalopay customer support.
You only answer to question about Zalopay to provide helpful answer to user who want to learn more about Zalopay and services provided by Zalopay
### Input:
{}
### Response:
{}
"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(samples):
questions = samples["question"]
answers = samples["answer"]
texts = []
for answer, question in zip(questions, answers):
text = zalopay_prompt.format(answer, question) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
def train(dataset):
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 8,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps = 20,
max_steps = 120,
learning_rate = 5e-5,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
trainer_stats = trainer.train()
if __name__ == '__main__':
samples = []
with open("data.jsonl", encoding='UTF-8', mode="r") as f:
for line in f:
samples.append(json.loads(line))
dataset = load_dataset("json", data_files="./data.jsonl", split="train")
dataset = dataset.map(formatting_prompts_func, batched=True)
# dataset = formatting_prompts_func(samples)
train(dataset)
To train,run:
python train.py
6.2.3. How it works
Use the finetuned model (adapter) with vllm
vllm serve /data/fin-advisor/model/Qwen2-7B-Instruct --enable-lora --lora-modules zalopay-lora=output_qwen --max-lora-rank 64
*output_qwen is default finetune script output
Q: "Nạp tiền điện thoại thế nào?"
Chat response: Để nạp tiền điện thoại vào Zalopay, bạn cần thực hiện các bước sau: Bước 1: Chọn số điện thoại cần nạp Bước 2: Chọn nguồn tiền, xác nhận thanh toán và hoàn tất.
6. Conclusion
Since publishing this blog, I’ve got some question why using LLM for recommendation task as it’s not built for recommendation. Some advantage of using LLM, especially for our POC use case:
- We do not need to write a lot of code, around 100 line of code can provide acceptable result based on specific user context (ie their History)
- We do not have to build and rebuild model everytime we introduce new usecase. When we have new service, just add it to vector database and it works.
- ML models which is being used to do recommendation are mostly built using 2 approaches: Linear Regression Model or Logistic Regression Model, Those model removes duplications compared to manual crafting rule based engine, but still they provide binary (yes/no) or probability answer. Example, you can build model to predict probability a user should be suggested to use telco or not, to recommend more than one usecase, you have to build 2 models.
- We can programmatic recommend action to user because LLM understands the context. Example: it’s 6AM, base on history {history} of this user, please recommend 2 services for him/her → the answer can be Grab or Movie or FnB. We do not have to build model to recommend services for Morning/Afternoon/Night etc. I know we can accomplish this with Logistic Regression model, but again it will take time and only provide binary answer.